These 4 weeks are very challenging. In my very first week of coding period I implemented LSMR solver. For implementing I have gone through different research paper and implementation in SciPy for understanding the algorithm and how that works. As I have been reading about the matrix solvers from mid of community bonding period, I am confident that algorithm will work well. But this not happend, performance comparision of CuPy LSMR(that I implemented) and SciPy LSMR shows that CuPy implementation is taking much more time (around 10-20 fold) to converge to solution.
Intro to Nsight Systems
After discussing this problem with mentors they told me that reason for this problem is that the algorithm is calling the cupy kernel like crazy. They advised me to profile my code using NVIDIA Nsight Systems.
And Nsight Systems help me a lot to inderstand the kernel calls (it takes me around 2 days to learn how use this). This tools produces the timeline of each process and calls made during execution of program. Following is my first ever CPU and GPU profile of any program on Nsight System.

Using Raw Kernels to reduce kernel calls
Looking at he problem mentors suggested me to use raw kernels to overcome and reduce the number of kernel calls made during the execution. But before that I tried implementing the Givens rotation from the CUDA source into CuPy (my implementation) and use that rotation in my implementation of LSMR. But doing so I got no improvement in performance.
As our main aim was to reduce the number of kernel calls. But problem that I faced was to select which way should I use to merge the individual kernel calls one way is to compute only matrix-vector multiplication and vector arithmetic on GPU, and do the scalar arithmetic on the host with syncing the results of the GPU computation earlier. And other is to write raw kernels for several operation to merge them to single kernel call. My mentor suggested that the former one will be easy to implement but might not have very good performance. So I chose latter (as this was also suggested previously so I was already working on this method).
Change in plan
All this goes for around 2 weeks from beginning of the coding period and I have not done any thing special till now. So my mentor advised me to try simple thing from my proposed work so I don’t feel stuck at a point. I followed what was advised to me, I planned to work simultaneously on implementing the linear algebra routine and add distributions to the new Generator.
After all that to refresh my mind I had taken 1 day break. I planned to implemented binomial distribution for new random number Generator and also try to implement the raw kernel. I thought to start with writing raw kernels. From different ways to write raw kernel in cupy I used cupy.fuse which is easiest ways to define custom kernel in python. So I come up with the following implementation but I have some error in this implementation. I discussed this with mentors and they told me that cupy.fuse has some limitation, cupy fuse is only ok when having several elementwise kernels fused together, but when we mix different shapes this will give no improvement in performance. In the mean time I also implemented my second solver for linear system MINRES but has same error as they both make large number of individual kernel calls.
Following is the statistics for CUDA API calls and Kernel calls:
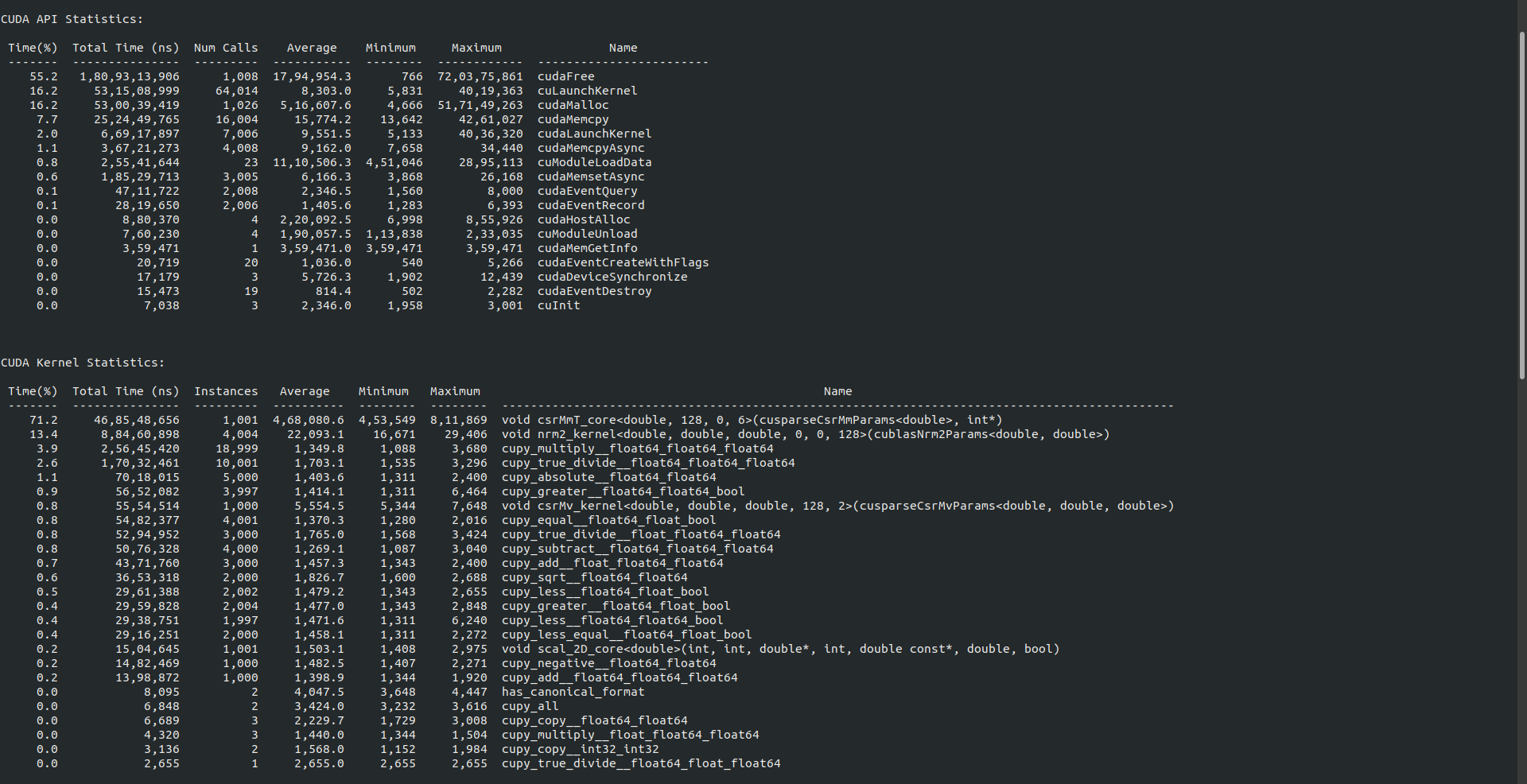
I implemented binomial distribution, but things are not going well for me. Due to some urgent personal reason I was not able to work for a week and I informed about this to my mentor and he understood my situation. As soon as I came back, I started adding tests for the binomial distribution that I added before the break. But still, the problem of the solver was not solved yet, will try to finish that before next blog.